
Bir e-ticaret sitesinde ürün kataloğunu ele alalım: bazı ürünlerin rengi vardır, bazılarının bedeni, bazılarının hiçbir ek özelliği yoktur. İlişkisel bir veritabanında bu farklılığı modellemek, boş sütunlar biriktirmek ya da karmaşık ek tablolar kurmak anlamına gelir. MongoDB gibi belge tabanlı bir NoSQL veritabanı, tam bu noktada işi kolaylaştırıyor. Bu yazıda NoSQL'in ne olduğunu, MongoDB'nin pratikte nasıl çalıştığını ve hangi durumlarda gerçekten tercih edilmesi gerektiğini somut örneklerle ele alıyorum.
NoSQL tam olarak ne anlama gelir?
NoSQL, "Not Only SQL" ifadesinin kısaltmasıdır ve verileri geleneksel satır-sütun tablolarının dışında saklayan veritabanı sistemlerini kapsar. Bu, tek bir teknoloji değildir; belge veritabanları (MongoDB, CouchDB), anahtar-değer depoları (Redis, DynamoDB), sütun tabanlı sistemler (Cassandra) ve graf veritabanları (Neo4j) gibi birbirinden farklı yaklaşımları bir araya getirir.
Ortak nokta, katı bir şemaya bağlı kalmamalarıdır. İlişkisel bir veritabanında bir tabloya yeni sütun eklemek genellikle bir migration gerektirir. NoSQL'de ise her kayıt kendi yapısını taşıyabilir. Bu esneklik, veri modeli sık değişen ya da başlangıçta tam olarak belli olmayan projelerde büyük avantaj sağlar.
NoSQL'in ortaya çıkışı tesadüf değildir. 2000'lerin sonunda Google, Amazon ve Facebook gibi şirketler, milyarlarca kaydı tek bir sunucuya sığdıramayacakları bir ölçekle karşılaştı. İlişkisel veritabanlarının dikey ölçeklendirme sınırı, yani daha güçlü tek bir sunucu almak, bu ölçekte pratik olmaktan çıktı. Bu şirketlerin geliştirdiği dağıtık sistem yaklaşımları zamanla MongoDB, Cassandra gibi açık kaynak projelere dönüştü ve bugün herkesin kullanabileceği araçlar hâline geldi.
Belge, anahtar-değer, sütun ve graf modelleri arasındaki fark, aslında hangi soruyu sık sorduğunuzla ilgilidir. Bir kullanıcının tüm profilini tek seferde çekmek istiyorsanız belge modeli uygundur. Milisaniyeler içinde tek bir anahtarla veri okumak istiyorsanız Redis gibi anahtar-değer modeli daha hızlıdır. "Bu kullanıcının arkadaşının arkadaşları kim" türünden ilişki ağırlıklı sorular içinse graf veritabanı doğal bir çözüm sunar.
MongoDB'de veri nasıl saklanır?
MongoDB, en yaygın kullanılan belge tabanlı NoSQL veritabanıdır ve verileri JSON'a benzeyen BSON (Binary JSON) formatında, belgeler hâlinde saklar. BSON, düz JSON'a göre tarih ve ikili veri gibi ek tipleri destekler; ikili formatı sayesinde ayrıştırması da daha hızlıdır. Bir kullanıcı kaydı şöyle görünebilir:
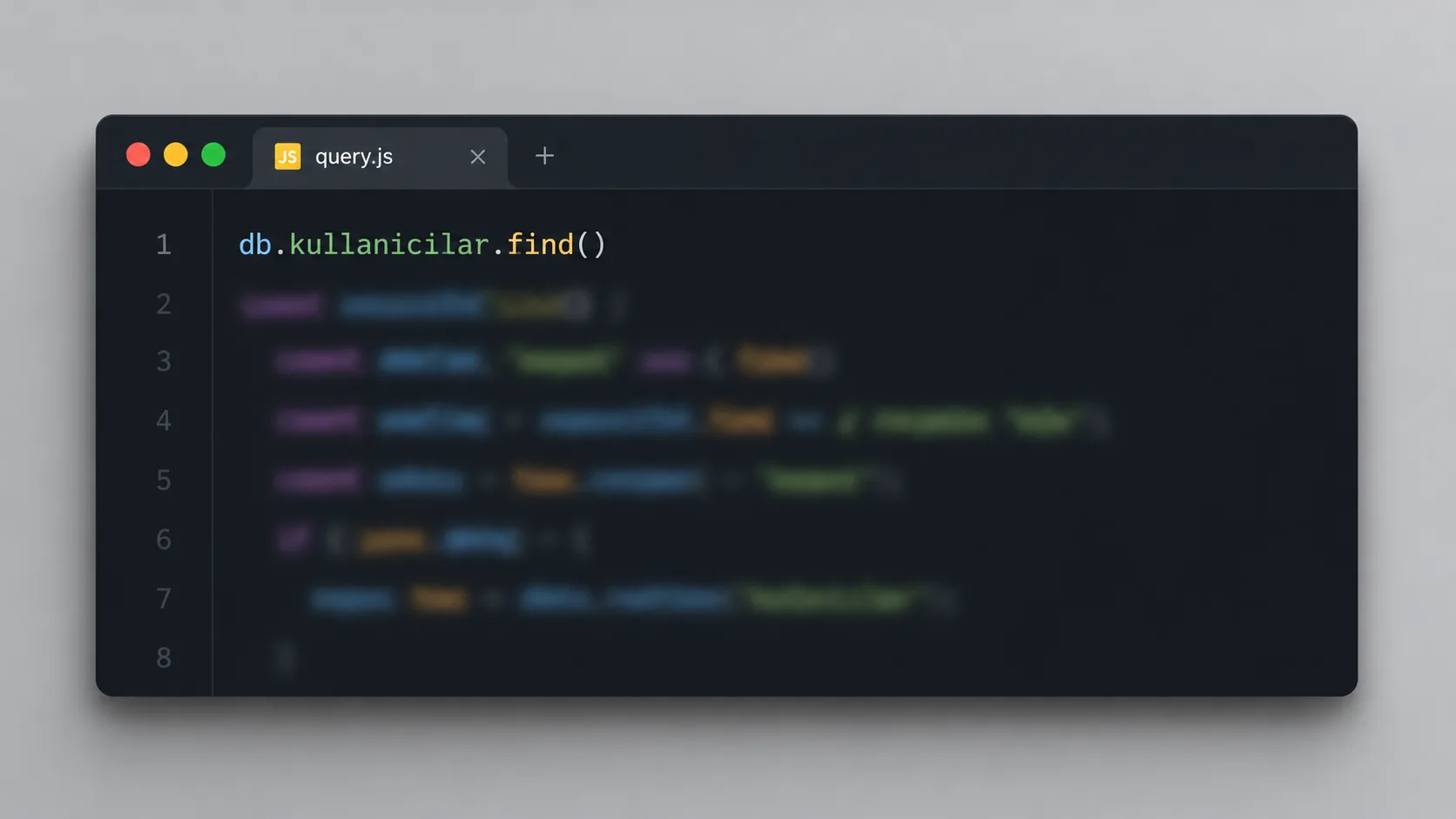
{
"_id": ObjectId("64f1a2b3c4d5e6f7a8b9c0d1"),
"ad": "Ayşe Yılmaz",
"email": "[email protected]",
"adresler": [
{ "tip": "ev", "sehir": "İstanbul" },
{ "tip": "is", "sehir": "Ankara" }
],
"aktif": true
}
Bu tek belge, ilişkisel bir veritabanında genellikle üç ayrı tabloya (kullanıcılar, adresler, adres_tipleri) bölünürdü. MongoDB'de ilgili veri tek belgede toplanır. Bu yaklaşıma "gömme" (embedding) denir ve sık birlikte okunan veriler için sorguyu tek adıma indirir.
Belgeler koleksiyonlar içinde tutulur. Bir koleksiyon, ilişkisel dünyadaki tabloya benzer ama şema zorunluluğu taşımaz. Temel işlemler şöyle görünür:
// Belge eklemek
db.kullanicilar.insertOne({ ad: "Mehmet Kaya", email: "[email protected]" })
// Sorgulamak
db.kullanicilar.find({ "adresler.sehir": "İstanbul" })
// Güncellemek
db.kullanicilar.updateOne({ email: "[email protected]" }, { $set: { aktif: false } })
Sorgu dilinin JavaScript nesnelerine bu kadar yakın olması, MongoDB'yi Node.js gibi ekosistemlerde çalışan geliştiriciler için özellikle sezgisel kılar. find(), updateOne(), deleteOne() gibi metodlar SQL'deki SELECT, UPDATE, DELETE komutlarının karşılığıdır; sözdizimi ise SQL yerine JavaScript nesnelerine benzer.
Bu benzerlik, öğrenme eğrisini özellikle ön uç veya Node.js arka uç geliştiricileri için kısaltır.
NoSQL ne zaman gerçekten mantıklı?
Her proje için NoSQL doğru seçim değildir; bu yüzden hangi senaryolarda öne çıktığını netleştirmek gerekir. Veri modeliniz sık değişiyorsa, örneğin bir MVP'de her hafta yeni alanlar ekliyorsanız, MongoDB'nin şema esnekliği migration derdinden kurtarır. Yüksek trafikli, yatay ölçeklendirme gerektiren sistemlerde de NoSQL avantajlıdır; veriyi birden fazla sunucuya (shard) dağıtmak ilişkisel veritabanlarına göre daha doğaldır.
Aşağıdaki tablo iki yaklaşımı hızlıca karşılaştırır:
| Kriter | İlişkisel (PostgreSQL, MySQL) | NoSQL (MongoDB) |
|---|---|---|
| Şema | Katı, önceden tanımlı | Esnek, belge bazlı |
| İlişkiler | JOIN ile güçlü | Gömme veya referans ile |
| Ölçeklendirme | Genellikle dikey | Yatay (sharding) doğal |
| Tutarlılık | Güçlü (ACID) | Genellikle nihai tutarlılık |
| İdeal senaryo | Finansal işlemler, karmaşık raporlama | Değişken şema, hızlı prototipleme |
Buna karşılık banka hesap hareketleri veya sipariş-ödeme gibi güçlü tutarlılık ve karmaşık JOIN gerektiren senaryolarda ilişkisel bir veritabanı hâlâ daha güvenli bir seçimdir. MongoDB, 4.0 sürümünden itibaren çoklu belge işlemlerini (transactions) destekler; ama ilişkisel veritabanlarının onlarca yıllık ACID garantisiyle aynı olgunlukta değildir.
Pratikte birçok orta ölçekli şirket, "polyglot persistence" adı verilen bir yaklaşım benimser: kullanıcı profilleri ve ürün kataloğu MongoDB'de, ödeme kayıtları ve muhasebe verisi PostgreSQL'de tutulur. Bu, dogmatik bir "ya hep ya hiç" seçimi yerine, her veri türü için en uygun aracı kullanma mantığına dayanır. Küçük bir ekip için iki veritabanını birden yönetmek ek operasyonel yük getirir; ama orta-büyük ölçekte bu ayrım genellikle kendini amorti eder.
Ölçeklendirme kararı da erken düşünülmesi gereken bir konudur. MongoDB'de sharding, veriyi bir "shard key" seçimine göre birden fazla sunucuya dağıtır. Yanlış seçilen bir shard key, verinin sunuculara dengesiz dağılmasına (hotspot) yol açabilir. Bu yüzden sharding'e geçmeden önce, uygulamanın en sık hangi alana göre sorgu yaptığını iyi analiz etmek gerekir.
Gömme mi, referans mı: veri modelleme kararı
MongoDB'de en kritik tasarım kararı, ilişkili veriyi tek belgede mi gömeceğiniz yoksa ayrı koleksiyonlarda referansla mı tutacağınızdır. Bir blog yazısı ve yorumları örneğini ele alalım.
// Gömme yaklaşımı: yorumlar yazının içinde
{
"baslik": "MongoDB'ye Giriş",
"yorumlar": [
{ "kullanici": "ali", "metin": "Faydalı yazı" },
{ "kullanici": "veli", "metin": "Teşekkürler" }
]
}
// Referans yaklaşımı: yorumlar ayrı koleksiyonda
{ "_id": 1, "baslik": "MongoDB'ye Giriş" }
{ "yazi_id": 1, "kullanici": "ali", "metin": "Faydalı yazı" }
Yorum sayısı azsa ve her zaman yazıyla birlikte gösteriliyorsa gömme yaklaşımı mantıklıdır; tek sorguda her şeyi çekersiniz. Ama bir yazı binlerce yorum alabilirsa, belge boyutu MongoDB'nin 16 MB belge sınırına yaklaşabilir ve referans yaklaşımı daha sürdürülebilir hâle gelir. Bu karar, ilişkisel veritabanlarındaki normalizasyon alışkanlığının tam tersi yönde düşünmeyi gerektirir.
Bu ters düşünme biçimi, MongoDB'ye yeni başlayanların en çok zorlandığı noktadır. İlişkisel veritabanlarında öğretilen "veriyi tekrarlama, normalize et" kuralı, MongoDB'de bazen doğrudan performans kaybına yol açar; çünkü her JOIN'e denk gelen işlem, MongoDB'de ayrı bir sorgu anlamına gelir. Denormalizasyon, yani bazı veriyi bilinçli olarak tekrarlamak, MongoDB'de sık kullanılan ve tamamen kabul edilebilir bir tekniktir.
- Sık birlikte okunan, birlikte değişen veri: gömün
- Büyük, bağımsız büyüyen veya paylaşılan veri: referans kullanın
- Belge boyutu 16 MB sınırına yaklaşıyorsa: referansa geçin
- Sık güncellenen alt veri (örneğin stok sayısı): ayrı tutmak güncelleme maliyetini azaltır
Performans için indeksleme nasıl çalışır?
MongoDB, indekslemeden önce sorguları _id dışında tam koleksiyon taraması (collection scan) ile çalıştırır. Bu, küçük koleksiyonlarda sorun yaratmaz ama milyonlarca belgede sorgu süresini saniyelere çıkarabilir. Sık sorgulanan alanlara indeks eklemek, MongoDB'yi bir ikili arama ağacı gibi çalıştırır ve sorgu süresini dramatik biçimde kısaltır.
// email alanına indeks eklemek
db.kullanicilar.createIndex({ email: 1 })
// hangi sorgunun indeks kullanıp kullanmadığını görmek
db.kullanicilar.find({ email: "[email protected]" }).explain("executionStats")
explain() çıktısında COLLSCAN görüyorsanız, o sorgu indekssiz çalışıyor demektir; production'a çıkmadan önce mutlaka kontrol edilmesi gereken bir detaydır. Bileşik indeksler, yani birden fazla alanı birlikte indeksleyen yapılar, sık filtrelenen alan kombinasyonları için değerlidir. Ama her indeks yazma işlemini biraz yavaşlattığı için, her alana körü körüne indeks eklemek de yanlıştır.
Aggregation pipeline, MongoDB'nin bir diğer güçlü tarafıdır. Verileri gruplama, filtreleme ve dönüştürme işlemlerini tek bir sorguda zincirlemenizi sağlar. Örneğin şehir bazında toplam sipariş tutarını hesaplamak için $match, $group ve $sort aşamalarını art arda kullanabilirsiniz. Karmaşık raporlama ihtiyaçları için bu pipeline, uygulama tarafında elle veri işlemekten çok daha verimli çalışır.
Küçük bir projede MongoDB kullanmalı mısınız?
Bu soru genellikle proje büyüklüğünden çok veri yapısının doğasına bağlıdır. Hızlı bir prototip yapıyorsanız ve veri modelinizin nasıl evrileceğinden emin değilseniz, MongoDB'nin şema esnekliği geliştirme hızını artırır; migration yazmadan yeni alanlar eklersiniz. Buna karşılık verileriniz baştan itibaren net ilişkilere sahipse, örneğin kullanıcılar, siparişler ve ödemeler gibi birbirine sıkı bağlı tablolar söz konusuysa, PostgreSQL gibi bir ilişkisel veritabanı JOIN'lerin doğal gücü sayesinde daha az kod yazmanızı sağlar.
MongoDB'yi denemek için resmi MongoDB Atlas ücretsiz katmanı ya da yerel bir Docker konteyneri yeterlidir. Temel CRUD işlemlerini öğrendikten sonra gerçek öğrenme veri modelleme kararlarında başlar; bu yüzden küçük bir kişisel projeyle pratik yapmak, teoriyi okumaktan çok daha hızlı öğretir.
Docker ile yerel bir MongoDB örneği ayağa kaldırmak tek satırlık bir komuttur:
docker run -d -p 27017:27017 --name mongo-test mongo:latest
Bu komut, varsayılan ayarlarla çalışan bir MongoDB konteyneri başlatır ve 27017 portundan bağlantı kabul eder. MongoDB Compass gibi görsel bir istemciyle bağlanıp verileri arayüz üzerinden incelemek, sorgu dilini öğrenirken özellikle faydalıdır. Komut satırına geçmeden önce veri yapısını gözle görmek, gömme veya referans kararlarını daha somut hâle getirir.
MongoDB'nin resmi dokümantasyonu, veri modelleme desenleri (embedding ve referencing) konusunda ayrıntılı ve güncel rehberler sunar. Production'a geçmeden önce bu dokümantasyonu okumak, ilerideki performans sorunlarının çoğunu baştan önler. Programlar kategorisindeki diğer yazılar, veritabanı seçimi ve mimari kararlar konusunda ek bağlam sağlayabilir.
Yazan Celil Uyanikoglu
Bilgisayar mühendisiyim; 25 yılı aşkın süredir bilgi işlem sektörünün içindeyim. Bu blogu 2020'de, işimde her gün karşılaştığım sorunların çözümlerini bir yere yazmak için açtım: Linux, güvenlik, tarayıcılar, yapay zeka araçları. Yazdığım her rehberi önce kendi bilgisayarımda ya da sunucumda deniyorum; çalıştığını görmediğim adımı yayınlamam. Hatalı ya da eskimiş bir şey görürsen iletişim sayfasından yaz — düzeltirim.


Henüz yorum yok.
Sohbete katıl. Yorumlar yayınlanmadan önce moderasyondan geçer.